In two earlier blog posts, I have described various
pieces of
my custom web framework that I used to actively develop many years ago. The framework is quite
modular -- every concern, such as layout management, data management, the editor, and the gallery, are separated into packages that can be deployed independently, so that web applications only have to include what they actually need.
Although modularity is quite useful for a variety of reasons, the framework did not start out as being modular in the beginning -- when I just started developing web applications in PHP, I did not reuse anything at all. Slowly, I discovered similarities between my projects and started sharing snippets of common functionality between them. Gradually, I learned that keeping these common aspects up to date became a burden. As a result, I developed a "
common framework" that I reused among all my PHP projects.
Having a common framework for my web application projects reduced the amount of required maintenance, but introduced a new drawback -- its
size kept growing and growing. As a result, many simple web applications that only required a small subset of the framework's functionality still had to embed the entire framework, making them unnecessarily big.
Today, a bit of extra PHP code is not so much of a problem, but around the time I was still actively developing web applications, many shared web hosting providers only offered a small amount of storage capacity, typically just a few megabytes.
To cope with the growing size of the framework, I decided to
modularize the code by separating the framework's concerns into packages that can be deployed independently. I "invented" my own conventions to integrate the framework packages into web applications:
- In the base directory of the web application project, I create a lib/ directory that contains symlinks to the framework packages.
- In every PHP script that displays a page (typically only index.php), I configure the include path to refer to the packages' content in the lib/ folder, such as:
set_include_path("./lib/sblayout:./lib/sbdata:./lib/sbcrud");
- Each PHP module is responsible for loading the desired classes or utility functions from the framework packages. As a result, I ended up writing a substantial amount of require() statements, such as:
require_once("data/model/Form.class.php");
require_once("data/model/field/HiddenField.class.php");
require_once("data/model/field/TextField.class.php");
require_once("data/model/field/DateField.class.php");
require_once("data/model/field/TextAreaField.class.php");
require_once("data/model/field/URLField.class.php");
require_once("data/model/field/FileField.class.php");
After my (approximately) 8 years of absence from the PHP domain, I discovered that a tool has been developed to support convenient construction of modular PHP applications:
composer. Composer is heavily inspired by the
NPM package manager, that is the defacto package delivery mechanism for
Node.js applications.
In the last couple of months (it progresses quite slowly as it is a non-urgent side project), I have decided to get rid of my custom modularity conventions in my framework packages, and to adopt composer instead.
Furthermore, composer is a useful deployment tool, but its scope is limited to PHP applications only. As frequent readers may probably already know, I use
Nix-based solutions to deploy
entire software systems (that are also composed of non-PHP packages) from a single declarative specification.
To be able to include PHP composer packages in a Nix deployment process, I have developed a generator named:
composer2nix that can be used to generate Nix deployment expressions from composer configuration files.
In this blog post, I will explain the concepts of
composer2nix and show how it can be used.
Using composer
Using composer is generally quite straight forward. In the most common usage scenario, there is typically a PHP project (often a web application) that requires a number of dependencies. By changing the current working folder to the project directory, and running:
$ composer install
Composer will obtain all required dependencies and stores them in the
vendor/ sub directory.
The
vendor/ folder follows a very specific organisation:
$ find vendor/ -maxdepth 2 -type d
vendor/bin
vendor/composer
vendor/phpdocumentor
vendor/phpdocumentor/fileset
vendor/phpdocumentor/graphviz
vendor/phpdocumentor/reflection-docblock
vendor/phpdocumentor/reflection
vendor/phpdocumentor/phpdocumentor
vendor/svanderburg
vendor/svanderburg/pndp
...
The
vendor/ folder structure (mostly) consists two levels: the outer directory defines the namespace of the packages and the inner directory the package names.
There are a couple of folders deviating from this convention -- most notably, the
vendor/composer directory, that is used by composer to track package installations:
$ ls vendor/composer
autoload_classmap.php
autoload_files.php
autoload_namespaces.php
autoload_psr4.php
autoload_real.php
autoload_static.php
ClassLoader.php
installed.json
LICENSE
In addition to obtaining packages and storing them in the
vendor/ folder,
composer also generates
autoload scripts (as shown above) that can be used to automatically make code units (typically classes) provided by the packages available for use in the project. Adding the following statement to one of your project's PHP scripts:
require_once("vendor/autoload.php");
suffices to load the functionality exposed by the packages that composer installs.
Composer can be used to install both
runtime and
development dependencies. Many development dependencies (such as
phpunit or
phpdocumentor) provide command-line utilities to carry out tasks. Composer packages can also declare which executables they provide. Composer automatically generates symlinks for all provided executables in the:
vendor/bin folder:
$ ls -l vendor/bin/
lrwxrwxrwx 1 sander users 29 Sep 26 11:49 jsonlint -> ../seld/jsonlint/bin/jsonlint
lrwxrwxrwx 1 sander users 41 Sep 26 11:49 phpdoc -> ../phpdocumentor/phpdocumentor/bin/phpdoc
lrwxrwxrwx 1 sander users 45 Sep 26 11:49 phpdoc.php -> ../phpdocumentor/phpdocumentor/bin/phpdoc.php
lrwxrwxrwx 1 sander users 34 Sep 26 11:49 pndp-build -> ../svanderburg/pndp/bin/pndp-build
lrwxrwxrwx 1 sander users 46 Sep 26 11:49 validate-json -> ../justinrainbow/json-schema/bin/validate-json
For example, you can run the following command-line instruction from the base directory of a project to generate API documentation:
$ vendor/bin/phpdocumentor -d src -t out
In some cases (the composer documentation often discourages this) you may want to install end-user packages
globally. They can be installed into the global composer configuration directory by running:
$ composer global require phpunit/phpunit
After installing a package globally (and adding:
$HOME/.config/composer/vendor/bin directory to the
PATH environment variable), we should be able to run:
$ phpunit --help
The composer configuration
The deployment operations that composer carries out are driven by a configuration file named:
composer.json. An example of such a configuration file could be:
{
"name": "svanderburg/composer2nix",
"description": "Generate Nix expressions to build PHP composer packages",
"type": "library",
"license": "MIT",
"authors": [
{
"name": "Sander van der Burg",
"email": "svanderburg@gmail.com",
"homepage": "http://sandervanderburg.nl"
}
],
"require": {
"svanderburg/pndp": "0.0.1"
},
"require-dev": {
"phpdocumentor/phpdocumentor": "2.9.x"
},
"autoload": {
"psr-4": { "Composer2Nix\\": "src/Composer2Nix" }
},
"bin": [ "bin/composer2nix" ]
}
The above configuration file declares the following configuration properties:
- A number of meta attributes, such as the package name, description, license and authors.
- The package type. The type: library indicates that this project is a library that can be used in another project.
- The project's runtime (require) and development (require-dev) dependencies. In a dependency object, the keys refer to the package names and the values to version specifications that can be either:
- A semver compatible version specifier that can be an exact version (e.g. 0.0.1), wildcard (e.g. 1.0.x), or version range (e.g. >= 1.0.0).
- A version alias that directly (or indirectly) resolves to a branch in the VCS repository of the dependency. For example, the dev-master version specifier refers to the current master branch of the Git repository of the package.
- The autoloader configuration. In the above example, we configure the autoloader to load all classes belonging to the Composer2Nix namespace, from the src/Composer2Nix sub directory.
By default, composer obtains all packages from the
Packagist repository. However, it is also possible to consult other kinds of repositories, such as external HTTP sites or VCS repositories of various kinds (including Git, Mercurial and Subversion).
External repositories can be specified by adding a '
repositories' object to the composer configuration:
{
"name": "svanderburg/composer2nix",
"description": "Generate Nix expressions to build PHP composer packages",
"type": "library",
"license": "MIT",
"authors": [
{
"name": "Sander van der Burg",
"email": "svanderburg@gmail.com",
"homepage": "http://sandervanderburg.nl"
}
],
"repositories": [
{
"type": "vcs",
"url": "https://github.com/svanderburg/pndp"
}
],
"require": {
"svanderburg/pndp": "dev-master"
},
"require-dev": {
"phpdocumentor/phpdocumentor": "2.9.x"
},
"autoload": {
"psr-4": { "Composer2Nix\\": "src/Composer2Nix" }
},
"bin": [ "bin/composer2nix" ]
}
In the above example, we have defined
PNDP's GitHub repository as an external repository and changed the version specifier of
svanderburg/pndp to use the latest Git master branch.
Composer uses a version resolution strategy that will parse composer configuration files and branch names in all repositories to figure out where a version can be obtained from and takes the first option that matches the dependency specification. Packagist is consulted last, making it possible for the user to override dependencies.
Pinpointing dependency versions
The version specifiers of dependencies in a
composer.json configuration file are
nominal and have some drawbacks when it comes to reproducibility -- for example, the version specifier:
>= 1.0.1 may resolve to version
1.0.2 today and to
1.0.3 tomorrow, making it very difficult to exactly reproduce a deployment elsewhere at a later point in time.
Although direct dependencies can be easily controlled by the user, it is quite difficult to control the version resolutions of the transitive dependencies. To cope with this problem, composer will always generate
lock files (
composer.lock) that pinpoint the exact dependency versions (including all transitive dependencies) the first time when it gets invoked (or when
composer update is called):
{
"_readme": [
"This file locks the dependencies of your project to a known state",
"Read more about it at https://getcomposer.org/doc/01-basic-usage.md#composer-lock-the-lock-file",
"This file is @generated automatically"
],
"content-hash": "ca5ed9191c272685068c66b76ed1bae8",
"packages": [
{
"name": "svanderburg/pndp",
"version": "v0.0.1",
"source": {
"type": "git",
"url": "https://github.com/svanderburg/pndp.git",
"reference": "99b0904e0f2efb35b8f012892912e0d171e9c2da"
},
"dist": {
"type": "zip",
"url": "https://api.github.com/repos/svanderburg/pndp/zipball/99b0904e0f2efb35b8f012892912e0d171e9c2da",
"reference": "99b0904e0f2efb35b8f012892912e0d171e9c2da",
"shasum": ""
},
"bin": [
"bin/pndp-build"
],
...
}
...
]
}
By bundling the
composer.lock file with the package, it becomes possible to reproduce a deployment elsewhere with the exact same package versions.
The Nix package manager
Nix is a package manager whose main purpose is to build all kinds of software packages from source code, such as GNU Autotools, CMake, Perl's MakeMaker, Apache Ant, and Python projects.
Nix's main purpose is not be a build tool (it can actually also be used for building projects, but this application area is still highly experimental). Instead, Nix manages dependencies and
complements existing build tools by providing dedicated build environments to make deployments reliable and reproducible, such as clearing all environment variables, making files read-only after the package has been built, restricting network access and resetting the files' timestamps to 1.
Most importantly, in these dedicated environments Nix ensures that only
specified dependencies can be found. This may probably sound inconvenient at first, but this property exists for a good reason: if a package unknowingly depends on another package then it may work on the machine where it has been built, but may fail on another machine because this unknown dependency is missing. By building a package in a pure environment in which all dependencies are known, we eliminate this problem.
To provide stricter purity guarantees, Nix isolates packages by storing them in a so-called "Nix store" (that typically resides in:
/nix/store) in which every directory entry corresponds to a package. Every path in the Nix store is prefixed by hash code, such as:
/nix/store/2gi1ghzlmb1fjpqqfb4hyh543kzhhgpi-firefox-52.0.1
The hash is derived from all build-time dependencies to build the package.
Because every package is stored in its own path and variants of packages never share the same name because of the hash prefix, it becomes harder for builds to accidentally succeed because of undeclared dependencies. Dependencies can only be found if the environment has been configured in such a way that the Nix store paths to the packages are known, for example, by configuring environment variables, such as:
export PATH=/nix/store/5vyssyqvbirdihqrpqhbkq138ax64bjy-gnumake-4.2.1/bin.
The Nix expression language and build environment abstractions have all kinds of facilities to make the configuration of dependencies convenient.
Integrating composer deployments into Nix builder environments
Invoking
composer in a Nix builder environment introduces an additional challenge -- composer is not only a tool that does build management (e.g. it can execute script directives that can carry out arbitrary build steps), but also
dependency management. The latter property conflicts with the Nix package manager.
In a Nix builder environment, network access is typically restricted, because it affects reproducibility (although it still possible to hack around this restriction) -- when downloading a file from an external site it is not known in advance what you will get. An unknown artifact influences the outcome of a package build in unpredictable ways.
Network access in Nix build environments is only permitted in so-called
fixed output derivations. For a fixed output derivation, the output hash must be known in advance so that Nix can verify whether we have obtained the artifact we want.
The solution to cope with a conflicting dependency manager is by
substituting it -- we must let Nix obtain the dependencies and force the tool to only execute its build management tasks.
We can populate the
vendor/ folder ourselves. As explained earlier, the
composer.lock file stores the exact versions of pinpointed dependencies including all transitive dependencies. For example, when a project declares
svanderburg/pndp version
0.0.1 as a dependency, it may translate to the following entry in the
composer.lock file:
"packages": [
{
"name": "svanderburg/pndp",
"version": "v0.0.1",
"source": {
"type": "git",
"url": "https://github.com/svanderburg/pndp.git",
"reference": "99b0904e0f2efb35b8f012892912e0d171e9c2da"
},
"dist": {
"type": "zip",
"url": "https://api.github.com/repos/svanderburg/pndp/zipball/99b0904e0f2efb35b8f012892912e0d171e9c2da",
"reference": "99b0904e0f2efb35b8f012892912e0d171e9c2da",
"shasum": ""
},
...
}
...
]
As can be seen in the code fragment above, the dependency translates to two kinds of pinpointed source objects -- a
source reference to a specific revision in a Git repository and a
dist reference to a zipball containing a snapshot of the given Git revision.
The reason why every dependency translates to two kinds of objects is that composer supports two kinds of installation modes: source (to obtain a dependency directly from a VCS) and dist (to obtain a dependency from a zipball).
We can translate the 'dist' reference into the following Nix function invocation:
"svanderburg/pndp" = {
targetDir = "";
src = composerEnv.buildZipPackage {
name = "svanderburg-pndp-99b0904e0f2efb35b8f012892912e0d171e9c2da";
src = fetchurl {
url = https://api.github.com/repos/svanderburg/pndp/zipball/99b0904e0f2efb35b8f012892912e0d171e9c2da;
sha256 = "19l7i7adp76bjf32x9a2ykm0r5cgcmi4wf4cm4127miy3yhs0n4y";
};
};
};
and the 'source' reference to the following Nix function invocation:
"svanderburg/pndp" = {
targetDir = "";
src = fetchgit {
name = "svanderburg-pndp-99b0904e0f2efb35b8f012892912e0d171e9c2da";
url = "https://github.com/svanderburg/pndp.git";
rev = "99b0904e0f2efb35b8f012892912e0d171e9c2da";
sha256 = "15i311dc0123v3ppa69f49ssnlyzizaafzxxr50crdfrm8g6i4kh";
};
};
(As a sidenote: we need the
targetDir property to provide compatibility with
the deprecated PSR-0 autoloading standard. Old autoload packages can be stored in a sub folder of a package residing in the
vendor/ structure.)
To generate the above function invocations, we need more than just the properties provided by the
composer.lock file. Since download functions in Nix are fixed output derivations, we must compute the output hashes of the downloads by invoking a Nix prefetch script, such as
nix-prefetch-url or
nix-prefetch-git. The
composer2nix generator will automatically invoke the appropriate prefetch script to augment the generated expressions with output hashes.
To ensure maximum compatibility with composer's behaviour, the dependencies obtained by Nix must be
copied into to the
vendor/ folder. In theory, symlinking would be more space efficient, but experiments have shown that some packages (such as
phpunit) may attempt to load the project's autoload script, e.g. by invoking:
require_once(realpath("../../autoload.php"));
The above require invocation does not work if the dependency is a symlink -- the require path resolves to a path in the Nix store (e.g.
/nix/store/...). The parent's parent path corresponds to
/nix where no autoload script is stored. (As a sidenote: I have decided to still provide symlinking as an option for deployment scenarios where this is not an issue).
After some experimentation, I discovered that composer uses the following file to track which packages have been installed:
vendor/composer/installed.json. The contents appears to be quite similar to the
composer.lock file:
[
{
"name": "svanderburg/pndp",
"version": "v0.0.1",
"version_normalized": "0.0.1.0",
"source": {
"type": "git",
"url": "https://github.com/svanderburg/pndp.git",
"reference": "99b0904e0f2efb35b8f012892912e0d171e9c2da"
},
"dist": {
"type": "zip",
"url": "https://api.github.com/repos/svanderburg/pndp/zipball/99b0904e0f2efb35b8f012892912e0d171e9c2da",
"reference": "99b0904e0f2efb35b8f012892912e0d171e9c2da",
"shasum": ""
},
...
},
...
]
Reconstructing the above file can be done by merging the contents of the
packages and
packages-dev objects in the
composer.lock file.
Another missing piece in the puzzle is the autoload scripts. We can force composer to dump the autoload script, by running:
$ composer dump-autoload --optimize
The above command generates an optimized autoloader script. A non-optimized autoload script dynamically inspects the contents of the package folders to load modules. This is convenient in the development stage of a project, in which the files continuously change, but in production environments this introduces quite a bit of load time overhead.
Since packages in the Nix store can never change after they have been built, it makes no sense to generate a non-optimized autoloader script.
Finally, the last remaining practical issue, is PHP packages providing command-line utilities. Most executables have the following
shebang line:
#!/usr/bin/env php
To ensure that these CLI tools work in Nix builder environments, the above shebang must be subsituted by the PHP executable that resides in the Nix store.
After carrying out the above described steps, running the following command:
$ composer install --optimize-autoloader
is simply just a formality -- it will not download or change anything.
Use cases
composer2nix has a variety of use cases. The most obvious one is to use it to package a web application project with Nix instead of
composer. Running the following command generates Nix expressions from the composer configuration files:
$ composer2nix
By running the following command, we can use Nix to obtain the dependencies and generate a package with a
vendor/ folder:
$ nix-build
$ ls result/
index.php vendor/
In addition to web applications, we can also deploy command-line utility projects implemented in PHP. For these kinds of projects it make more sense generate a
bin/ sub folder in which the executables can be found.
For example, for the
composer2nix project, we can generate a CLI-specific expression by adding the
--executable parameter:
$ composer2nix --executable
We can install the composer2nix executable in our Nix profile by running:
$ nix-env -f default.nix -i
and then invoke
composer2nix as follows:
$ composer2nix --help
We can also deploy third party command-line utilities directly from the Packagist repository:
$ composer2nix -p phpunit/phpunit
$ nix-env -f default.nix -iA phpunit-phpunit
$ phpunit --version
The most powerful application is not the integration with Nix itself, but the integration with other Nix projects. For example, we can define a
NixOS configuration running an Apache HTTP server instance with PHP and our example web application:
{pkgs, config, ...}:
let
myexampleapp = import /home/sander/myexampleapp {
inherit pkgs;
};
in
{
services.httpd = {
enable = true;
adminAddr = "admin@localhost";
extraModules = [
{ name = "php7"; path = "${pkgs.php}/modules/libphp7.so"; }
];
documentRoot = myexampleapp;
};
...
}
We can deploy the above NixOS configuration as follows:
$ nixos-rebuild switch
By running only one simple command-line instruction, we have a running system with the Apache webserver serving our web application.
Discussion
In addition to
composer2nix, I have also been responsible for developing
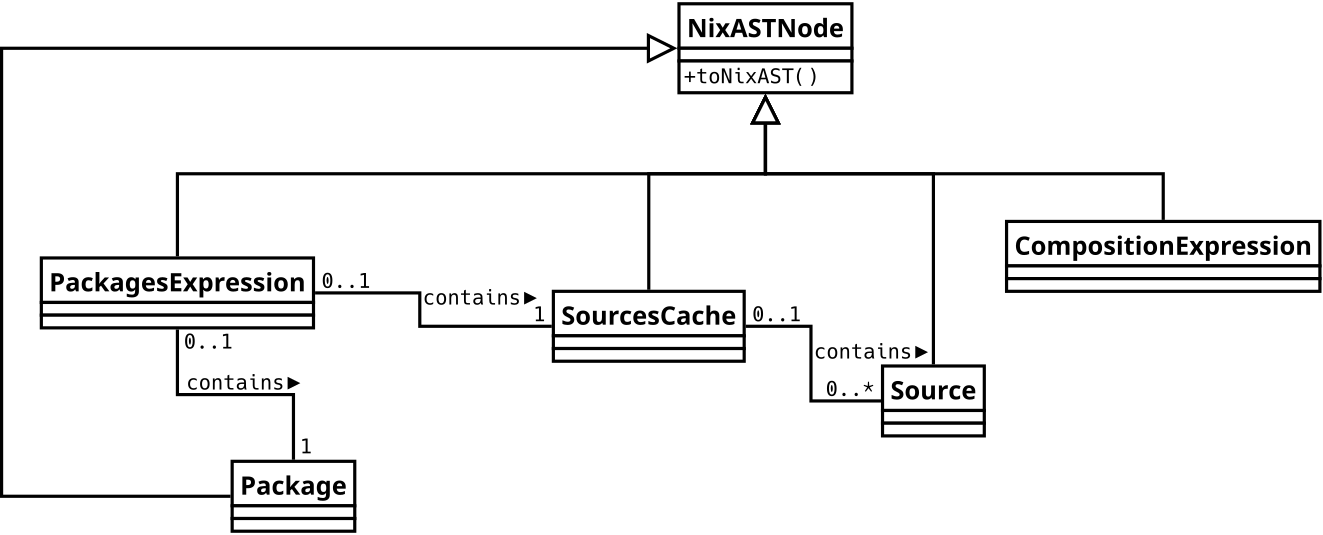
node2nix, a tool that generates Nix expressions from NPM package configurations. Because composer is heavily inspired by NPM, we see many similarities in the architecture of both generators. For example, both generate the same kinds of expressions (a builder environment, a packages expression and a composition expression), have a similar separation of concerns, and both use an internal DSL for generating Nix expressions (
NiJS and
PNDP).
There are also a number of conceptual differences -- dependencies in NPM can be private to a package or shared among multiple packages. In composer, all dependencies in a project are shared.
The reason why NPM's dependency management is more powerful is because Node.js uses the
CommonJS module system. CommonJS considers each file to be a unique module. This, for example, makes it possible for one module to load a version of a package from a certain filesystem location and another version of the same package from another filesystem location within the same project.
By contrast, in PHP, isolation is accomplished by the namespace declarations in each file. Namespaces can not be dynamically altered so that multiple versions can safely coexist in one project. Furthermore, the
vendor/ directory structure makes it possible to store only one variant of a package.
Despite the fact that composer's dependency management is less powerful makes constructing a generator much more straightforward compared to NPM.
Another feature that composer supports for quite some time, and NPM until very recently is pinpointing/locking dependencies. When generating Nix expressions from NPM package configurations, we must replicate NPM's dependency resolving algorithm. In composer, we can simply take whatever the
composer.lock file provides. The lock file saves us from replicating the dependency lookup process making the generation process considerably easier.
Acknowledgments
My implementation is not the first attempt that tries to integrate composer with Nix. After a few days of developing, I discovered
another attempt that seems to be in a very early development stage. I did not try or use this version.
Availability
composer2nix can be obtained from
Packagist and
my GitHub page.
Despite the fact that I did quite a bit of research,
composer2nix should still be considered a prototype. One of its known limitations is that it does not support fossil repositories yet.